
深度学习的音乐创作综述(part.2)
4 仪器和编排
正如我们在第 2 节中提到的,乐器和编排是正在创作的音乐流派中的基本元素,并且可以通过使用特定的乐器或编排作品的方式来代表每个作曲家的特征。一个例子是贝多芬在交响乐中使用的编排,它改变了音乐的创作方式。乐器是研究如何将相似或不同的乐器以不同的数量组合在一起,以创建合奏。编排是对得分相似或不同部分的选择和组合。由此,我们可以将乐器作为作品的颜色,将编排与作品的美学方面联系起来。乐器和编排对我们感知音乐的方式以及音乐的情感部分都有巨大的影响,但是,尽管它们代表了音乐的基本部分,但情感超出了这部作品的范围。
4.1 从复调音乐到多乐器音乐的生成
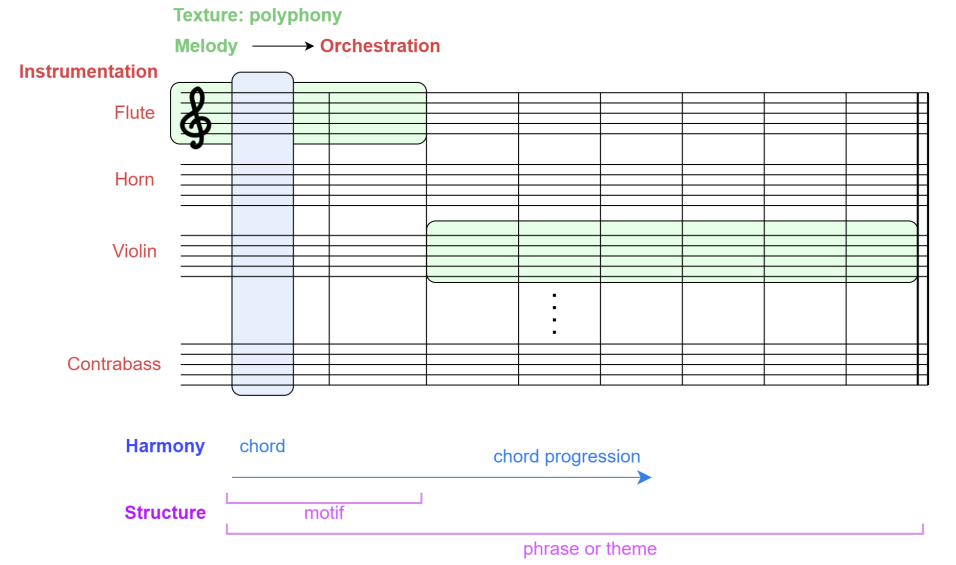
在基于计算机的音乐创作中,我们可以将乐器和编排概念组合在多乐器或多音轨音乐中。然而,用于多仪器生成的基于 DL 的模型并不完全符合这些概念。基于多乐器 DL 的模型为多个乐器生成复调音乐,但是,生成的音乐是否遵循连贯的和声进程?由此产生的编曲在乐器和编排方面是连贯的,还是基于 DL 的模型只是生成多乐器音乐而不考虑每个乐器或编曲的特色?在第 3 节中,我们展示了复调音乐的产生可以创作出具有一定和声感的音乐,但在面对多乐器音乐时,最重要的一个方面是要考虑乐器和合奏的特色。决定合奏中有多少和哪些乐器,以及如何在它们之间划分旋律和伴奏,是 DL 音乐生成中尚未解决的问题。近年来,构建从头开始生成音乐的 DL 模型面临着这一挑战,这些模型可以是人类可以选择合奏乐器的交互式模型。还有一些模型可以修复仪器或棒材。我们描述了这些模型,并回答了第 4.2 节中暴露的问题。在图 4 中,我们展示了具有多乐器生成模型的类似输出的乐谱的音乐基本原理的方案。
4.2 从零开始多仪器生成
第一个可以生成多音轨音乐的模型已经被广泛提出。在多音轨音乐生成之前,一些模型为给定的旋律或和弦生成鼓音轨。这些模型的一个例子是 Kang 等人在 2012 年提出的模型。该模型用自动鼓发生器以给定的比例伴随旋律。后来,在 2017 年,Chu 等人使用分层 RNN 生成了有鼓的流行音乐。
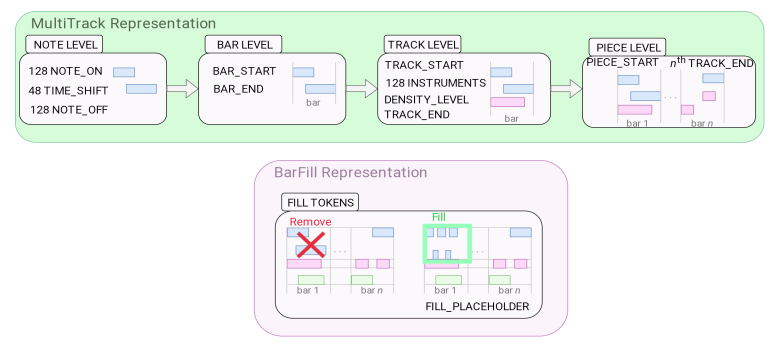
音乐生成中最常用的架构之一是生成模型,如 GANs 和 VAE。2017 年推出的 MuseGAN 是第一个被考虑和最知名的多音轨音乐生成模型。然后,更多的模型实现了多仪器生成任务,并在 2020 年晚些时候发布了基于自动编码器的其他模型,如 MusAE。最近用于生成音乐的另一大类 NN 架构是 Transformers。最著名的 Transformer 音乐生成模型是钢琴复调音乐生成的 Music Transformer。2019 年,Donahue 等人提出了用于多音轨音乐生成的 LakhNES,2020 年,Ens 等人提出了一种条件多音轨音乐产生模型(MMM),该模型基于 LakhNES,并通过将多个音轨连接成单个序列来改进该先前模型的令牌表示。该模型使用 MultiInstrument 和 BarFill 表示,如图 5 所示。在图 5 中,我们展示了 MultiInstrument 表示,它包含 MMM 模型用于生成音乐的令牌,以及用于修复的 BarFill 表示,即生成一个小节或几个小节,但保持作品的其余部分。
从作曲过程的角度来看,这些模型不是编排或乐器化的,而是从头开始或通过修复来创作音乐。这意味着这些模型不选择乐器的数量,也不生成与所选乐器相关的高质量旋律或伴奏内容。例如,MMM 模型为遵循乐器音色特征的预定义乐器生成旋律内容,但当在保留其他曲目的同时修复或重新创建单个乐器时,有时很难遵循其他乐器的组成键。这使我们得出结论,用于音乐生成的多乐器模型专注于端到端的生成,但在乐器或编排方面仍然不能很好地工作,因为它们仍然无法决定生成的音乐中的乐器数量。他们为他们训练的合奏生成音乐,如 LakhNES,或者他们采用预定义的曲目来生成每个曲目的内容。最近的模型,如 MMM,在多乐器生成方面打开了人类和人工智能之间的互动,这将允许更好地跟踪人类的作曲过程,从而改进使用多乐器生成的音乐。
5 评估和指标
音乐生成中的评价可以根据测量 DL 模式的输出的方式来划分。Ji 等人区分了客观评价和主观评价。在音乐中,有必要从主观的角度来衡量结果,因为这是一种评估类型,告诉我们与人类创造力相比,模型带来了多少创造力。有时,计算模型结果指标的客观评估可以让我们了解这些结果的质量,但很难找到将其与创造力概念联系起来的方法。在本节中,我们将展示最先进的模型如何从客观和主观的角度衡量其结果的质量。
5.1 客观评价
客观评估使用一些数字度量来衡量模型的性能及其输出的质量。在音乐生成中,存在比较为不同目的训练的模型和使用不同数据集训练的模型的问题,因此我们对最先进的模型中使用的最常见的度量进行了描述。Ji 等人通过区分模型度量和音乐度量或描述性统计,以及其他方法,如模式重复或剽窃检测。
当你想衡量一个模型的性能时,根据用于生成音乐的 DL 模型,最常用的指标是:loss 损失、perplexity 混淆、 BLEU 分数、precision 精度(P)、recall 回忆(R)或 F-core(F1)。通常,这些度量用于比较为相同目的构建的不同 DL 模型。
损失通常用于从数学角度显示模型的输入和输出之间的差异,而另一方面,混淆告诉我们一个模型具有的泛化能力,这更多地与模型如何生成新音乐有关。例如,音乐转换器使用损失和混淆来比较不同转换器架构之间的输出,以验证模型,TonicNet 仅将损失用于相同的目的,MusicVAE 仅使用指示模型具有的重建质量的度量,但是不使用任何度量来在其他 DL 音乐生成模型之间进行比较。
关于与音乐特别相关的指标,即考虑音乐描述符的指标,我们可以发现这些指标有助于衡量作品的质量。根据 Ji 等人,这些指标可以分为四类:音高相关、节奏相关、和声相关和风格转移相关。音高相关指标,如音阶一致性、音调误差音、空小节比率或使用的音高类别数量,是衡量音高属性的指标。节奏相关指标考虑了音符的持续时间或模式,例如,节奏变化、同时出现的三个或四个音符的数量或重复音高的持续时间。和声相关指标测量和弦的熵、距离或覆盖范围。这三个度量类别被 MuseGAN、C-RNN-GAN 或 JazzGAN 等模型使用。最后,与风格转换相关的技术有助于了解迭代与所需风格的距离有多近或多远。其中包括风格契合、内容保留或转移强度。
5.2 主观评价
主观观点决定了生成的音乐在创造力和新颖性方面的表现,也就是说,生成的音乐可以在多大程度上被视为艺术。虽然艺术涉及创造力和美学。Sternberg 和 Kaufman 将创造力定义为做出新颖且适合任务的贡献的能力,通常带有附加的成分,如高质量的、令人惊讶的或有用的。创造力需要对音乐知识的本质和使用有更深入的理解。根据 Ji 等人的说法,音乐质量的定量评估与人类判断之间缺乏相关性,这意味着音乐生成模型也必须从主观角度进行评估,这将使我们深入了解模型的创造性。主观评价中最常用的方法是听力测试,它通常由人类来区分机器生成的音乐和人类创造的音乐。这种方法被称为图灵测试,用于测试 DeepBach。在这个模型中,来自不同音乐体验群体的 1.272 人参加了测试。该测试表明,模型越复杂,输出就越好。MusicVAE 还进行了听力测试和 Kruskal-Wallis H-test,以验证模型的质量,得出的结论是,使用分层解码器时,模型表现更好。MuseGAN 还对 144 名用户进行了听力测试,他们被分为具有不同音乐体验的小组,但用户必须在 1-5 个范围内投票决定一些预先定义的问题:和声、节奏、结构、连贯性和整体评分。
其他收听方法需要对生成的音乐进行评分,这被称为并排评分。根据模型的生成目标,还可以向听众询问一些关于模型的创造性或生成作品的自然性等问题。在听力测试中需要记住的一件重要的事情是选择参加测试的人群的可变性(如果听众是具有音乐理论基础知识的音乐学生,如果他们是业余爱好者,因此他们没有任何音乐知识,或者如果他们是专业音乐家)。听众必须有相同的刺激,也必须听相同的片段,并有相同的人类创造的片段作为参考(如果适用的话)。听觉疲劳也必须考虑在内,因为如果长时间听类似的样本,听众可能会产生偏见。
话虽如此,我们可以得出结论,当涉及到音乐生成时,听力测试是必不可少的,因为它可以反馈模型的质量,而且它们也可以是找到正在研究的更好的 NN 架构或 DL 模型的一种方法。
6 讨论
我们已经证明,音乐是一种结构化的语言模型,具有时间和和声的短期和长期关系,需要深入了解其所有见解才能建模。这一点,加上音乐中存在的各种流派和子流派,以及创作一首音乐作品所遵循的大量创作策略,使 DL 音乐生成领域成为一个不断发展和具有挑战性的领域。在描述了音乐创作过程和 DL 最近为音乐生成所做的工作后,我们现在将讨论第 1.3 节中提出的问题。
目前的DL模型是否能够产生具有一定创造力的音乐?
使用 DL 生成音乐的第一个模型使用了诸如 LSTM 之类的 RNN。这些模型可以生成注释,但在生成长期序列时失败了。这是因为这些 NN 没有处理音乐生成所需的长期序列。为了解决这个问题,并能够通过插入两个现有的基序或从分布中采样来生成短基序,创建了 MusicVAE。但由此产生了一些问题:现有主题之间的插值是否会在同一首音乐中产生有意义的高质量主题?如果我们使用 MusicVAE 来创建一个简短的主题,我们可以获得非常好的结果,但如果我们使用这种模型来生成与输入相似的较长短语或主题,这些插值可能会输出具有美感的主题,但有时它们不遵循输入所具有的任何节奏或音符方向(上升或下降)模式。因此,这些插值通常无法生成高质量的主题,因为模型不了解节奏模式和音符方向。此外,和弦进行通常有倒置,古典音乐中有规则,流行音乐、爵士乐或城市音乐中有风格限制,这些规则决定了每个和弦后面是另一个和弦。如果我们分析 DL 方法生成的复调旋律,则在和声内容方面缺乏质量,因为被训练来生成音乐的神经网络无法理解音乐语言中存在的所有这些复杂性,或者因为这些信息应该作为输入的一部分(例如作为令牌)传递给神经网络。
使用 DL 进行音乐创作的最佳 NN 架构是什么?
Transformer 架构已经与不同的注意力机制一起使用,这些机制允许对更长的序列进行建模。这方面的一个例子是 MMM 模型的成功,该模型使用 GPT-2 生成多音轨音乐。尽管该模型使用了预先训练的 Transformer 来生成文本,但它在和声和节奏方面生成了连贯的音乐。其他架构使用生成网络,如 GANs 或 VAE,以及这些架构中的 Transformers。这些模型的发展提高了提取高级音乐属性的可能性,如风格和在潜在空间中组织的低级特征。然后,这个潜在空间被用来在这些特征和属性之间进行插值,以基于现有作品和音乐风格生成新的音乐。
通过分析过去几年中使用 DL 生成音乐的神经网络模型和架构,没有一种特定的神经网络架构能更好地实现这一目的,因为可以用于构建音乐生成模型的最佳神经网络架构将取决于我们想要获得的输出。尽管如此,正如该领域的最新作品所表明的那样,Transformers 和 Generative 模型正在成为目前最好的替代品。两种模型的组合也是执行音乐生成的一个很好的选择,尽管这取决于我们想要生成的输出,有时最佳解决方案来自 DL 与概率方法的组合。另一个需要考虑的方面是,通常,音乐生成需要具有大量参数和数据的模型。我们可以通过将预先训练的模型作为我们在前几节中描述的一些最先进的模型来解决这个问题,然后对另一个 NN 架构进行微调。另一种选择是拥有一个预训练的潜在空间,该空间是通过像 MusicVAE 提出的那样用巨大的数据集训练一个大模型来生成的,然后利用预训练的潜伏空间训练一个数据较少的较小 NN,以调节音乐作品的风格,正如 MidiMe 提出的。
端到端的方法能生成完整的结构化音乐片段吗?
正如我们在第 3.2 节中所描述的,现在有一些基于结构模板的模型可以生成结构化音乐,但还没有一种端到端的方法可以创作结构化音乐作品。人类作曲家遵循的音乐创作过程类似于这种基于模板的方法。在不久的将来,人工智能很可能从头开始创作结构化音乐,但这里的问题是,用于音乐生成的人工智能模型是否会被用来从头开始创作整个音乐作品,或者这些模型是否会更有用,作为作曲家的辅助,从而作为人类与人工智能之间的互动。
带有 DL 的作曲作品只是对输入的模仿吗?还是 NN 可以生成训练数据中不存在的风格的新音乐?
当训练 DL 模型时,传递给 NN 的输入中的一些信息可以在输出中不做任何修改的情况下出现。即便如此,MusicVAE 和其他用于音乐生成的 DL 模型表明,新音乐可以在不模仿现有音乐或抄袭的情况下创作。模拟输入可能是过拟合的情况,这从来不是 DL 模型的目标。还应该考虑到,由于一首音乐中可能出现的乐器、音调、节奏或和弦种类繁多,在音乐的生成过程中很难进行剽窃。
神经网络应该像人类一样遵循同样的逻辑和过程来创作音乐吗?
我们发现,研究人员开始构建可以生成复调旋律的模型,但这些旋律在几小节后没有遵循任何方向。当 MusicVAE 问世时,可以生成高质量的主题,这鼓励了新的研究,利用过去的时间步长信息生成旋律。新的模型,如扩散模型,正在使用这种预先训练的模型来生成更长的序列,让旋律遵循模式或方向。我们还表明,有一些模型可以通过和弦进行来调节旋律,这是以流行音乐等风格创作音乐的方式。将人类的作曲方式与用于生成音乐的 DL 架构进行比较,我们可以看到这两个过程的一些相似之处,特别是在自回归模型中。自回归(AR)包括从过去的事件中预测未来的值。一些 DL 方法是自回归的,新模型试图通过获取过去时间步长的信息来生成更长的序列,这一事实类似于人类创作古典音乐的过程。
用于音乐生成的 DL 模型需要多少数据?
如果我们看看最先进的模型,这个问题可以得到部分回答。MusicVAE 使用 LMD,有 370 万首旋律、460 万个鼓型和 11.6 万个三重奏。Music Transformer 只使用了钢琴 e-Competition 中的 1.100 首钢琴作品来训练模型。其他模型,如 MMM,采用 GPT-2,这是一个预训练的具有大量文本数据的 Transformer。这让我们肯定,用于音乐生成的 DL 模型确实需要大量数据,特别是在训练生成模型或 Transformers 时,但采用预先训练的模型并进行迁移学习也是一个很好的解决方案,特别是对于符号音乐生成的实际数据集中没有表示的音乐流派和子流派。
目前的评估方法是否足以比较和衡量创作音乐的创造力?
正如我们在第 5 节中所描述的,有两种评估类别:客观评估和主观评估。现有方法之间的客观评价指标相似,但缺乏通用的主观评价方法。听力测试是最常用的主观评估方法,但有时图灵测试只要求区分基于计算机的作文和人类作文,不足以了解神经网络创作的作文的所有特征。该问题的解决方案是,如 MuseGAN 所提出的,提出与图 2 中所示的音乐特征的质量相关的一般问题,并在 DL 模型中使用相同的问题和相同的评级方法来设置一般的主观评估方法。
7 结论和未来工作
在本文中,我们概述了用于 DL 音乐生成的神经网络架构,描述了 DL 音乐生成中的最新技术,并讨论了在音乐生成中使用深度神经网络仍然存在的挑战。
使用 DL 架构和技术生成音乐(以及其他艺术内容)是一个不断增长的研究领域。然而,也存在一些悬而未决的挑战,比如生成有结构的音乐,分析生成音乐的创造力,以及建立可以帮助作曲家的互动模型。未来的工作应该专注于更好地建模长期关系(在时间轴和和声轴上),以便生成结构良好、和谐的音乐,在几小节后不会变得松散,以及修复或人工智能交互,这是近年来人们越来越感兴趣的任务。还有一个悬而未决的挑战与迁移学习或风格生成的条件有关,这使得大多数最先进的作品只关注相同的音乐风格,而不仅仅局限于公开数据集中的相同作者和流派,如 JSB Chorales 数据集或 Lakh MIDI 数据集。当涉及到多乐器的生成时,这项任务并不遵循人类的作曲过程,看到新的 DL 模型可能会很有趣,它们首先创作出高质量的旋律内容,然后自己或在人类的帮助下决定乐曲的乐器数量,并能够为每种乐器创作出符合其音色特征的高质量音乐。与 DL 音乐生成应该关注的方向有关的进一步问题,即建立可以从头开始生成高创意音乐的端到端模型,或者作曲家可以与人工智能交互的交互模型,是未来将要解决的任务,尽管人类与人工智能交互的趋势每天都在加快。
在使用 DL 的音乐创作中,还有更多悬而未决的问题不在本文的范围内。如果 NNs 是用受版权保护的音乐训练的,那么谁拥有 DL 生成的音乐的知识产权等问题。我们认为这将是商业应用中的一个重要关键。这里的主要关键是定义是什么使一个作品与其他作品不同,有几个特征在这里起着重要作用。正如我们在第 1 节中提到的,这些特征包括作品本身,也包括音色和用于创造乐器声音的效果。从作曲的角度来看,这是我们的研究范围,我们可以指出,当用 DL 生成音乐时,总是有可能生成与输入相似的音乐,有时生成的音乐具有直接取自输入的模式,因此必须从音乐理论的角度在这一领域进行进一步的研究,知识产权和科学,以定义是什么使作品与其他作品不同,以及如何注册 DL 生成的音乐。
我们希望本文中的分析将有助于更好地理解问题和可能的解决方案,从而为基于深度学习的音乐生成的整体研究议程做出贡献。