
音乐生成的人工智能综述:智能体、领域和前景(part.2)
6、模型
到目前为止,我们已经看到了音乐生成任务中常用的数据集以及可以帮助我们处理它们的软件。但是,哪些方法和神经网络架构被用于生成音乐?当前基于人工智能的模型用于音乐任务是因为它们正确地表示和学习音乐信息,还是仅仅因为它们在其他任务中表现良好?在本节中,我们将介绍音乐生成领域中使用的架构和方法。
机器音乐的产生始于20世纪50年代左右。机器和项目,如1957年的 ILLIAC Suite 、1964年 Koening 的 Project1 、20世纪80年代 David Cope 的 EMI ,以及 Iannis Xe nakis 的 Analogiques A 和 B 。20世纪80年代末,第一个使用神经网络的基于人工智能的模型受到算法合成的启发。 Lewis 在1988年使用了梯度下降法的训练和创造阶段。同样在1988年和1989年,Todd 定义了用于音乐应用的顺序网络。顺序网络使用的内存与已经产生的音符有反馈连接。1994年,Mozer 使用了 Elman 的 CONCERT 网络,该网络在给定可能候选音符的概率的情况下继续了一系列音符。除了这些先前的工作之外,已经提出了几种将不同的算法方法和神经网络架构结合用于音乐生成的工作。算法合成字段内部我们可以找到马尔可夫模型、生成文法、细胞自动机、遗传算法、过渡网络或 Caos 理论。这些模型可以以不同的风格和方式创作音乐,但新的深度学习方法比这些基于规则的方法更适合泛化。
A.模型架构
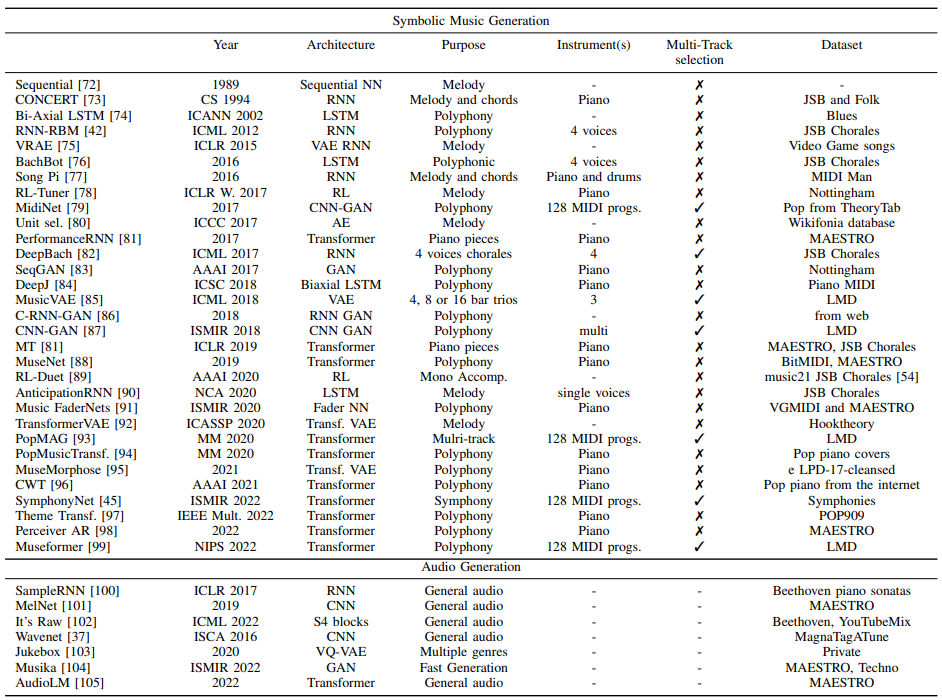
考虑到为每个模型选择的神经网络架构,我们有两大组方法:序列模型和生成模型。在表III中,我们提供了一些最先进的音乐生成模型的摘要。我们可以观察到模型是如何添加多轨道功能的,以及使用的架构是如何首先是RNN,现在的模型主要基于Transformers。我们还可以看到,强化学习(RL)在该领域和图神经网络(GNN)中都没有得到深入的探索。
【表三:最先进的音乐生成模型。旋律是指单声道旋律,而复调是指一种乐器,即钢琴或多种乐器的复调音乐】
1) 生成模型
生成模型基于变分贝叶斯(Variational Bayesian,VB)方法。ML的这个统计部分将统计推理问题视为优化问题。这些模型用于近似未观测变量的后验概率。在这个家族中,我们可以找到变分自编码器(VAE)、生成对抗性网络(GANs)、扩散模型(DM)等。
a) 变分自动编码器(VAE):VAE模型由 Kingma 和 Welling 于2013年引入。VAE的目标是将输入建模为连续概率分布,然后从学习的分布中解码新的数据点。该架构类似于自动编码器,在VAE的情况下,潜在变量形成了具有均值和方差的概率分布的潜在空间。编码器 qφ(z|x) 和解码器 pθ(x|z) 分别具有可学习参数 φ 和 θ 是概率的。在 VAE 中,编码器近似于 VB 证据下界(ELBO)中的真实后验分布 p(z|x) ,这使得能够将统计推理问题作为优化问题来面对。后验近似和似然近似由解码器参数化。在 Eq. 1 中,我们展示了 VAE 的损失函数,其对应于 ELBO 优化,并且由两个项组成:重建项和KL散度。
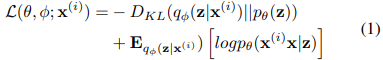
后验推理是通过最小化编码器或近似后验之间的 Kullback-Leibler(KL)分歧来完成的,而真正的后验推理则是通过最大化证据下界(ELBO)来完成的。换句话说,这意味着我们将试图通过捕捉输入数据的分布来重建输入。在这些模型中,梯度是用所谓的重新参数化技巧计算的。原始VAE模型有一些变体,如用于音频生成的 β-VAE 或 VQ-VAE 。基于VAE的符号音乐生成模型的示例是 MusicVAE ,基于 VQ-VAE 的音频生成模型是 Jukebox 。
b) 生成对抗性网络(GANs):Goodfellow 等人于 2014 年引入了生成对抗性网。这些模型是由两个神经网络组成的,这两个网络是按照两人的极小极大博弈(Eq.2)进行训练的。这些网络被称为生成器(G)和鉴别器(D)。生成器创建数据以试图在训练期间欺骗鉴别器,鉴别器学习区分生成器生成的真实数据和虚假数据。第一个用于音乐生成的多音轨模型 MuseGAN 就是使用 GAN 网络。
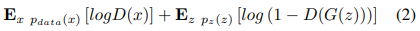
其中,x 是数据,z 是噪声变量, pz(z) 是在输入噪声变量上定义的先验,D 是判别器,G 是生成器函数。D(x) 被定义为 x 是真实数据而不是由生成器分布采样的数据的概率。
c) 扩散模型:扩散模型的灵感来自非平衡统计物理学。这些模型在2022年 DALLE 2 或 Stable Diffusion 等模型发布后开始流行。然而,与大多数 ML 研究一样,这些模型首先被用于计算机视觉领域。这些模型基于扩散步骤的马尔可夫链的构建,其中在正向过程中一步一步地将随机噪声添加到数据中,然后它们学习反向扩散过程,以在反向过程中从噪声中构建新的数据样本。扩散模型是通过固定的过程学习的,潜在变量具有与原始数据相同的高维度,这使它们不同于 VAE 和 GAN 。应用于音乐生成领域的扩散过程的一个例子是 Mittal 等人的工作。将其与 MusicVAE 相结合,以生成更长的序列。
有更多的生成模型和它们的特殊应用,但由于它们尚未在音乐生成领域中使用,我们将不再深入讨论它们。这些模型的例子是基于流的模型,其特征是构建对数据的可逆转换序列或流。
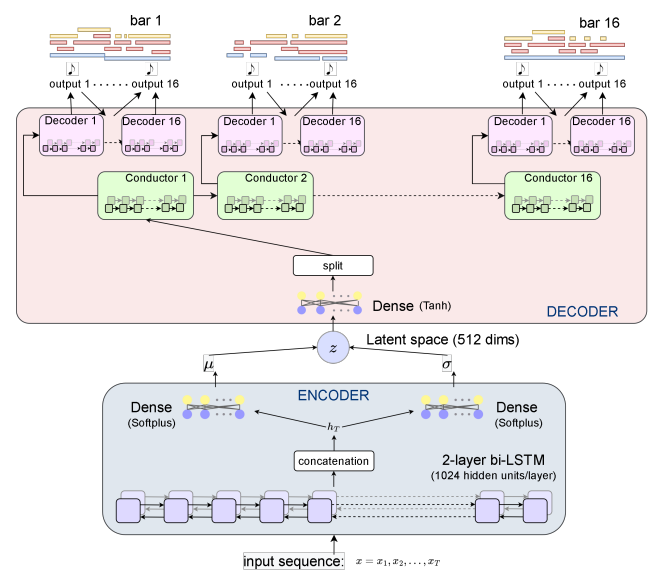
【图6:MusicVAE模型架构。我们可以观察到该模型如何呈现一个具有两个BLSTM网络的编码器和一个逐音符逐小节生成符号信息的分层解码器】
2) 自回归序列模型
序列模型与生成模型相比,通常使用自回归。自回归模型利用概率链式规则估计样本的密度(Eq.3)。
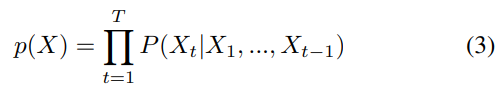
其中, Xt 是 T 个令牌序列中的一个令牌。令牌是依赖于域(音频帧、像素等)的表示。每个新令牌可以通过估计用于预测第 t 个令牌的先前令牌的条件密度来获得。符号音乐中的记号是音符事件,如音高、速度或时间增量。
a) 递归神经网络(RNN):递归神经网络是使用序列或时间序列数据的人工神经网络。这些网络的特点是其存储单元允许存储建模长期序列的信息,但它们存在消失梯度问题。一些常用的RNN是长短期记忆(LSTM)和门控循环单元(GRU)。在音乐生成领域,这些是第一批用于尝试生成具有长期依赖性的音乐的网络。Eck 和 Schmidhuber 在 2002 年的作品就是一个例子,该作品旨在从布鲁斯音乐中学习和弦和旋律。
b) 基于 Transformer 的模型:Transformers 由 Vaswani 等人于 2017 年推出。这些模型已经超越了以前的 RNN ,并被用于从 NLP 到计算机视觉领域的各种用途。这是因为由于作为这些模型核心的注意力机制,避免了 RNN 中常见问题的消失梯度。注意力机制是基于以前在检索系统中的工作,它是用三个矩阵计算的:键、查询和值。最初的 Transformer 使用了缩放的点积注意力或自注意力机制(Eq.4)。
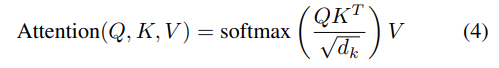
其中
$$
Q ∈ R^{d_{\text{model}} \times d_k},V ∈ R^{\text{d_{model}} \times d_{v}} 和K ∈ R^{\text{d_{model}} \times d_k}
$$
分别是查询、值和键,dmodel 是词汇表大小,在符号音乐中,它可以包含我们编码中包含的所有音高、持续时间、曲目和任何其他特征。
原论文还包括一个改进机制,以改进自我注意机制。多头注意力允许并行地进行注意力并关注来自不同位置的不同子空间的信息。在 Eq.5 中,我们展示了多头注意力的一般表达式。在注意力层的这种修改中,dk=dv=dmodel/h,其中 h 是头的数量。
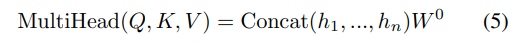
当 hi 是 i^t^ 的 head attention :
$$
h_i = Attention(QW^Q_i, KW^K_i, VW^V_i)
$$
自注意机制的复杂性是 O(L^2^d),其中 d 是层大小,L 是序列长度。这种二次算法最近被重新考虑,我们现在可以找到更有效的注意力实现,将算法的复杂性降低到线性。
近年来为 NLP 提出的 Transformer 模型已经用大量参数进行了训练,也可以称为大型语言模型(LLM)。这些模型的一个例子是基于 GPT 的模型、BERT 或 T5 。它们中的一些使用了原始 Transformers 提出的编码器-解码器,而其他一些(如GPT)只使用了偶尔注意(casual attention)的解码器。由于文本和音乐编码之间的关系以及我们可以用来执行从文本到音乐的迁移学习的预先训练的权重,这些LLM也是一些符号音乐生成模型的核心。
3) 强化学习
强化学习(RL)是一种基于复杂目标实现的 ML 方法。深度 RL 将深度神经网络与 RL 相结合,以近似 agent (智能体)需要学习与环境交互的函数。因此,RL 是从互动中学习的。当 agent 使用策略或规则集进行操作 a 以与环境的状态 s 进行交互并因此获得奖励 r 时,就会发生这种交互。每个交互定义一个新状态 s‘ 。agent 的目标是使奖励最大化。我们将 Q 定义为在状态 s 中采取任何行动 a 都能获得最大未来回报的最优函数。深度 Q 学习(deep Q-learning)使用深度神经网络对 Q 函数进行建模。生成音乐的 RL 模型的一个例子是 RL 调谐器。在这个模型中,LSTM 网络从 teacher 那里学习,这是一种包含音阶等音乐理论概念的 RL 算法。这允许网络学习不可微分的奖励函数。这是一种根据音乐原理控制生成音乐的好方法,但这方面的工作还不多,用于音乐生成的 RL 仍有待深入研究。RL 系统的另一个用途是在给定旋律的情况下生成伴奏,如RL Duet中所提出的。
B.输入表示
音乐表示根据我们要构建的模型的领域、用途和架构而有所不同。在符号域和音频域中,我们都可以找到输入数据的 1D 和 2D 表示。
1) 符号
符号音乐信息通常分为不同的层次:乐曲层次、曲目或乐器层次和小节层次。这种音乐组织不仅有助于训练 DL 模型,而且还允许在实际应用中进行评估、修复和通信。
a) 文件格式:我们可以找到多种存储符号音乐的文件格式。最常见的是 MIDI (乐器数字接口),因为音乐制作人和作曲家可以在数字音频工作区(DAW)中轻松修改它们。MIDI 文件包含作为事件的信息,但它们并不包含所有的音乐信息,如和弦或演奏属性,如动态。从 MIDI 编码符号音乐最常用的事件是音符打开(note on)和音符关闭(note off)(音符开始和结束的位置)、音高(音符的值从 0 到 128 )、存储施加到音符的压力的演奏属性的速度以及表示包含音符的乐器的程序号(也从 0 到 128 )。其他 MIDI 信息包括节奏或每分钟节拍(bpm)的变化以及按键的变化。用于训练 DL 模型的最常用数据集包含 MIDI 文件。其他符号格式是 MusicXML ,它在音乐属性方面比 MIDI 更丰富,因为它可以包含和弦等和声信息。ABC 记谱法也是一种常用的音乐记谱法。当涉及到为音乐生成开发 API 时,我们可以发送 JSON 格式或协议缓冲区(protobufs)的音乐信息。note-seq 和 musicaiz 库可以导出这种表示形式的音乐,muspy 只能导出 JSON 格式的音乐。
b) One-Hot Encoding:这种编码指的是具有基音时间维度的 2D 矩阵,其中矩阵值是二进制的。如果在某个时间步长(列),音高(行)对应于该时间步长中正在播放的任何音高,则该值等于 1,如果不是,则等于 0。
c) 钢琴独奏(pianoroll):钢琴独奏是音符事件的一种表现,可以属于某些乐器。
d) 序列编码:当训练序列模型时,有必要将输入音乐映射到令牌。与 NLP 一样,这些标记将音乐表示为 1D 向量中的一系列事件。在这篇文章中,我们找到了关于音符、结构、乐器等的信息。符号音乐的编码方式和表达时间增量单位的方法各不相同。PerformanceRNN 在 2017 年是第一个引入类似 MIDI 的事件作为数据结构的模型。这种编码已经被许多作品采用,最近基于 Transformer 的模型使用这种类型的数据结构,但以不同的方式对 MIDI 数据进行编码。音乐变换器(music transformer)通过音符和时间事件进行训练。音符事件是指以音符长度为单位测量时间增量或音符持续时间。例如,如果我们的单位是第 16 个音符,并且我们想用 delta 来表示四分之一音符的持续时间,那么我们的时间 delta 为 8,因为一个四分之一的音符中有 8 个第 16 个音节。时间事件不使用音符长度,而是使用以毫秒为单位的时间。有时,由于 MIDI 数据的性质或来源,它没有量化,选择音符长度作为单位可能会导致近似,这会使我们失去原始文件的一些凹槽。Music Transformer 建议使用时间增量作为 10ms 的单位,这会产生良好的结果,并尊重训练数据的性质。相比之下,多音轨音乐机(MMM)提出了以符号音符长度而不是毫秒进行时间编码。这种编码基于 LakhNES,并通过将多个音轨串联成具有时间偏移的单个线性序列来定义 MIDI 事件之间的时间,从而改进了其令牌表示。此模型使用 MultiInstrument 和 BarFill 表示。
MultiInstrument 表示包含 MMM 模型用于生成多音轨音乐的令牌,BarFill 表示用于修复小节,也就是说,将现有小节替换为模型通过保持前一小节和下一小节的音乐原理一致性生成的新小节。这是建立模型的重要一步,用户可以与之交互,并接近基于分数的表示。钢琴修复应用程序(PIA)类似于 MMM 编码,因为它也提供了类似 MIDI 的编码,但尽管定义了事件之间的时间偏移,它还是标记了音符的持续时间,因此 MMM 的 NOTE OFF 标记不存在于该编码中,并且 NOTE ON 和 time DELTA 分别由 PITCH 和 duration 标记替换。在复合词转换器(CWT)中引入的复合词根据其音乐属性将标记分组为复合词,也就是说,音符将由其属性或属性定义,即音高、持续时间和速度标记,而位置标记(如 Bar)将仅具有指示小节起始位置的 Bar 标记。
在表IV中,我们提供了训练序列模型的不同编码的摘要,在图 7 中,我们展示了用 musicaiz 提取的 MMM 标记化的示例,在图 8 中,我们展现了符号音乐编码的一般模式。请注意,需要符号音乐结构分析(MSA)来添加可能基于 SIA、SIATEC 和 COSIATEC 算法的部分标记。
【表IV:音乐生成中使用的编码——最先进的序列模型】


【图7:Pianooll 表示及其 MMM Track 编码的示例。在本例中,时间增量以刻度表示。我们可以观察到乐曲、音轨和第一小节是如何分别以 piece start、track start 和 bar start 标记开始的,以及音符是如何以音符的音高为值,以 NOTE ON 打开和以 NOTE OFF 关闭标记关闭的。在本例中,TIME DELTA 以记号表示】
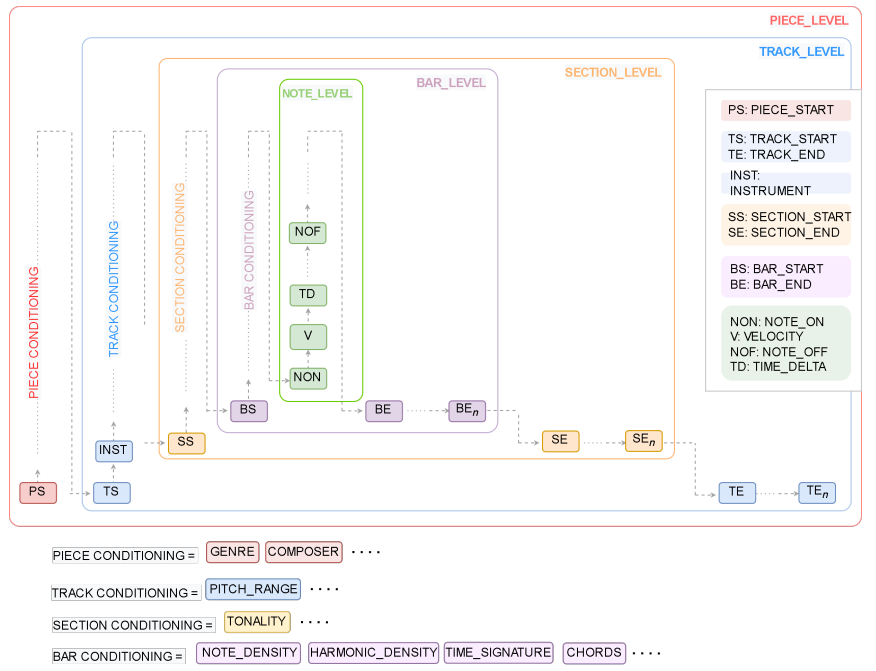
【图8:基于 MMM 的通用编码。该图显示了如何扩展 MMM 编码以调节不同级别的生成的一般方案配置。我们通过添加一个额外的级别来扩展原始 MMM 中提出的三个级别,该级别需要音乐结构检测或结构注释的特征提取算法。级别为:乐曲、乐器、小节、小节和音符级别。添加小节级标记可以允许在不需要用户手动指定或选择的情况下修复音乐短语、主题或小节】
e) 图:图神经网络(GNN)是最近的架构,需要将输入表示为图 G(V,e),其中 e 是边,V 是节点。在音乐生成领域,这种架构还没有得到深入的探索。Jeong 等人提出了音乐的第一个音符级图表示,其中节点表示音符,并边缘化音符之间的音乐关系。连续音符与同时演奏的音符(和弦)具有不同的边缘。在图 9 中,我们展示了Jeong等人提出的音乐图表示的例子。这种表示可以重新思考和扩展,以添加小节级别、曲目级别或乐曲级别的图,从而为音乐生成训练进一步的 GNN。请注意,此表示适用于 MusicXML 文件,其中音符的时间属性与小节中的节拍和细分完全对齐,因此为了使此表示适应 MIDI 文件,有必要量化或修改所提出的表示。
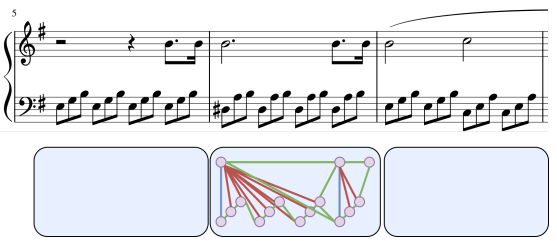
【图9:Jeong等人提出的音乐图形表示】
2) 音频
a)波形:波形是原始音频数据在时间上的幅度的 1D 表示。波形中要提到的一个重要参数是采样率或采样频率,它是信号中每秒采样的数量。
b) 声谱图:声谱图是音频生成模型中最常见的输入。频谱图是用短时傅立叶变换(STFT)获得的每个片段上的频谱的 2D 表示,短时傅立叶变换是用快速傅立叶变换(FFT)计算的。通常,使用梅尔谱图,它只是一个频率适应梅尔标度的谱图。使用对数 mel 频谱图对数地呈现高于某个阈值的频率也是常见的,因此频率比线性频谱图中的频率缩放得更好。
还有其他变换可以用于音乐生成,但其使用并不普遍。其中一个原因是,在 VAE 中,我们需要重建输入,然后执行频谱图的逆或变换以获得振幅和相位,这在诸如常数 Q 变换(CQT)的变换中是不可能的。有一些算法可以反转这些变换,但它们在数学上并不精确。小波是可逆的,但由于它们的高计算成本,它们不是音乐生成领域中常用的变换。此外,与 FFT 算法相比,这些变换中的一些变换具有较高的计算成本,FFT 算法比大多数其他变换更有效。
3) 数据增强
它包括修改输入数据以获得更多样本来训练模型。可以应用于输入数据的技术取决于域。在符号领域,我们可以通过转换乐曲的键来修改音乐数据。也就是说,在乐曲中的所有音高上加上或减去相同的半音值。其他可能的数据扩充技术是通过用其他和弦替换一些和弦来修改和弦进行。这将需要在乐曲中对当前和弦进行注释(或预测它们),并使替换连贯,以便最终的和声进程与新和弦连贯。我们应该注意这些修改,因为我们可能会放松作品的风格。例如,如果我们对一个模型进行条件处理以生成贝多芬的作品,如果我们将贝多芬的作品扩展到其他键,则模型可能输出的结果不会是我们预期的和声进行或键。然而,我们总是可以通过程序修改生成的音乐,使其遵循某些规则或将 DL 模型设置为特定的键或和弦。在音频领域,修改是基于输入的性质,而不是音乐方面。这是因为符号数据更容易修改,因为我们有关于音符、乐器等的信息,但在音频领域,我们没有这些信息(除非我们用预先训练的模型预测一些音乐特征)。因此,可以应用于音频音乐信号的最常见的技术是音高偏移、时间拉伸、噪声添加等。
C.输出形式
Briot 等人将音乐的输出性质定义为对音乐生成模型进行分类的方法之一。在这种情况下,由于在音频领域中,生成的音乐的输出形式取决于我们训练模型的数据集,我们将专注于符号音乐生成,在那里我们可以更容易地识别音乐术语中输出的性质。输出性质与音乐的结构和纹理原理有关,这取决于我们所看到的。一些音乐生成模型被训练来生成钢琴作品,而其他模型则提出了多乐器生成。一件作品中的乐器可能由模型本身或最终用户决定。这种分类是基于结构的分类,因为纹理是一个完全不同的概念。基于纹理的分类可以区分单声道和复调生成(我们可以在单乐器和多乐器作品中具有相同的纹理)。
1) 注重质感
a) 旋律生成与伴奏:旋律生成是音乐创作模式的最初目标之一。旋律是一系列音符,可以是单声道的,也可以是复调的。第一个组成旋律的模型产生了短期音符序列。随着 RNN 和语义模型的出现,提出了基于单元选择的工作。RNN 在该领域模型的开发中发挥了重要作用。自从 Eck 和 Schmidhuber 在 2002 年的工作以来,越来越多的模型使用 RNN 来创作音乐。这些模型的例子是 2016 年谷歌 Magenta 的 MelodyRNN 或 2017 年的 AnticipationRNN 。这些模型能够产生旋律,也能够产生跟随旋律的和弦,但它们并没有被开发成对位模型。对位是一种通过遵循一定的规则来组合旋律的技巧。2017 年的 DeepBach 是最早实现这一目标的模型之一。该模型是用 JSB Chorales 数据集训练的,该数据集包含 4 个在对位中机智的声音片段。DeepBach 的架构由 RNN 组成,并使用吉布斯采样(Gibbs sampling)来编写每个语音的音符,吉布斯采样是一种从多变量概率分布中获得近似观测序列的技术。此外,2017 年提出了 COCONET 。该模型由神经回归分布估计(NADE)模型与吉布斯采样相结合组成。
然而,这些模型无法产生新的或创造性的音乐创意,如高质量的主题。随着 VAE 等新生成模型的出现,Magenta 于 2018 年提出了 MusicVAE6。这个想法是在 VAE 的潜在空间中插入,创作 2 到 16 小节的短音乐片段。该模型是用 LMD 的旋律和三重奏(鼓,低音和旋律)进行训练的。MusicVAE 提出后,音乐生成领域旨在在新的基于 Transformer 的模型的卓越功能的指导下生成更长的序列或旋律文本生成。2018 年提出的带有螺旋式注意力机制的音乐转换器是最早使用注意力机制生成多语音音乐的模型之一。该模型是用 JSB Chorales 和 MAESTRO 数据集为精湛的钢琴进行训练的。2018 年出现了更多基于 Transformer 的模型,如 OpenAI 的 MuseNet 。2020 年发表的 PopMAG 也可以生成伴奏。对于 16 到 32 小节的音乐序列,即较长乐曲中的音乐部分,解决了长期依赖性。当涉及到上下文时,较长的序列无法记住以前的音乐想法的原因是注意力瓶颈。从 2020 年开始,有人提出了使用 VAE 和 Transformers 来生成新音乐并为长期背景建模的模型。PianoTree 、 TransformerVAE 就是这样的模型的例子。然而,这些模型中的任何一个都实现了生成具有高水平结构连贯性的长音乐片段的目标。使用扩散的模型的一个例子是 Mittal 等人提出的模型,该模型基于去噪扩散概率模型(DDPM)。该模型捕获 MusicVAE 2-bar 模型的 k=32 的 VAE 潜伏时间 zk 之间的时间关系。这允许将 MusicVAE 2 小节扩展到 64。然而,正如基于注意力的 mdoels 所发生的那样,这种方法既不能遵循主题或音乐理念,也不能连贯地延续它。新的基于注意力的模型,如使用交叉注意力来使用 4096 个令牌的上下文的 Perceiver AR,正在使用 MAESTRO 数据集进行训练,并且似乎可以学习和生成更长的音乐序列。
旋律生成的另一种方法是首先生成和弦序列,然后生成与和弦进行相匹配的旋律。这是一种人类也采用的创作方式。BebopNet 模型从爵士乐和弦中生成旋律,因为爵士乐和声比其他音乐流派更复杂。其他模型使用变分自动编码器(VAE)、生成对抗性网络或基于 GAN 的模型、端到端模型。ChordAL 生成一个和弦进程,该和弦进程被发送到旋律生成器,然后将输出发送到音乐风格处理器。
b) 结构:生成遵循高级结构的音乐是音乐生成领域的一个悬而未决的问题。生成结构化音乐的困难部分是模型实现这一点所需的高理解水平。更准确地说,该模型不仅需要学习节奏、旋律和和声是如何结合的,还需要记住几小节或几分钟前发生的音乐事件,以便开发或修改它们。音乐中的小节可能被建模为模板,或者可以通过模型学习。每种音乐流派都有自己的结构或部分标签,如摇滚或流行音乐的合唱和诗歌,或奏鸣曲形式的阐述、发展和重述。部分也可以用大写字母标记。过去,有一些模型提出了高层结构建模所需遵循的模板。Lattner 等人在 2018 年使用了自相似矩阵和卷积限制玻尔兹曼机(C-RBM)将结构强加给生成的音乐。其他作品试图开发自己学习音乐结构的模型。尽管使用注意力机制的新 DL 模型正在尝试生成更长的序列,但据我们所知,仍然没有能够生成结构化音乐的模型。使用交叉注意力机制或线性注意力的模型可能是实现这一目的的解决方案。使用 MAESTRO 数据集训练的 Perceiver AR 是可用于此目的的最新模型。尽管如此,它并没有根据音乐原理进行评估,这让我们怀疑它生成结构化音乐的能力。除了尝试在模型的架构中工作(这是最常见的方法)外,研究人员还可以开发检测符号数据结构的算法,以将结构标记添加到输入编码中,如我们在图 8 中提出的那样。这也将有助于修复的关注点。
c) 旋律协调:旋律协调是为现有旋律找到合适且连贯的和弦进行的过程。我们需要指出的事实是,有大量的和弦,因为我们可以从主音(半音音阶中的 12 个音符)构建它们,根据和弦的复杂性(三和弦、七和弦等),它们可以反转为一个、两个、三个或更多个反转,并且可以具有不同的质量(大、小、减、增等)。此外,一个和弦不能跟在词汇表中的所有和弦后面,因为和弦进行必须具有由每个和弦音调功能定义的连贯性。我们还必须区分旋律协调还是为多首曲目生成伴奏,但在我们看来,最后一个术语更多地与乐器有关。第一个面临这个问题的模型是基于隐马尔可夫模型(HMM)的,其性能优于 RNN。Eck 和 Schmidhuber 在 2002 年使用 LSTM 来学习旋律和和弦。最近,在 2019 年,LSTM 也被用于预测给定旋律的和弦伴奏。同样在 2019 年,巴赫涂鸦(使用 Coconet)被开发出来,以巴赫的风格为给定的旋律生成伴奏。近年来提出了更多使用 LSTM 的工作。
关于多音轨伴奏的生成,它可能被视为编排过程的一部分。旨在执行这项任务的模型是基于 GAN 的架构,用于实现引线板安排。2018 年的 MICA(多乐器联合编曲)和 2020 年的 MSMICA 是多音轨伴奏的一个例子。
d) 通过调节生成:音乐生成的一个重要特征是调节模型的能力。调节可以基于使模型遵循特定的音乐原则或继续给定的提示。由于研究人员提出的输入编码,基于 Transformer 的模型能够生成给定和弦序列的音乐。在这一领域,由于人机交互(HCI)研究的重要性,我们发现还有很多研究要做,并让用户通过将这些技术作为作曲过程的一部分来使用这些技术,例如,通过修复与用户音乐知识相匹配的不同作品级别和难度。
e) 风格转换:音乐可以有多种风格。流派是允许对音乐进行分类的东西。不同的流派有其特殊性,它们将不同的音乐原则结合在一起。在音乐生成领域,风格转换是指改变作品的流派,例如,将摇滚歌曲转换为古典歌曲。这是一项有趣的技术,因为没有每个音乐流派的数据集来训练大型 DL 模型,然而,如果我们的数据集很小,也可以进行迁移学习。在音乐生成领域,Hung 等人于 2019 年提出了爵士乐生成的递归 VAE 模型。在 DL 领域,Gatys 等人于 2016 年引入了风格转移。其目的是将样式特征应用于另一个图像中的图像。当涉及到音乐生成时,通过使用表示生成音乐的风格的嵌入或特征向量来改变音乐风格。MIDI-VAE(2018)是一个可以执行此任务的模型示例。得益于 VAE 的潜在空间,该模型将其中的风格编码为音高、动态和乐器特征的组合,使其能够生成复调音乐。正如我们之前提到的,一首音乐作品的风格是由作曲家如何结合音乐原理来定义的。除了使用音高和演奏属性对风格进行编码的 MIDI-VAE 之外,我们还可以找到其他模型,如 MusAE,它们也使用音高属性对音乐风格进行建模。除了这些使用音高属性的模型外,我们还可以找到使用和声和纹理属性对风格进行编码的模型,如 2020 年的 PianoTreeVAE、2021 年的 MuSeMorphse 和其他作品。
f) 修复:随着计算机视觉的新发展,可以组合两幅图像的风格或扩展现有的绘画,修复已成为最终用户的需求。修复是用与上一个和下一个音乐片段匹配的新颖内容替换音乐内容的能力,以保持作品的连贯性。在符号音乐中提供这种能力的模型的例子是钢琴修复应用程序(PIA)(2021)或 MMM 编码(2020)中提出的 BarFill 标记化。PIA 适用于钢琴作品,而 MMM 可以处理多音轨音乐。对模型的实验表明,对现有音乐的替换如何保持音乐方面的连贯性,如和声。然而,通过对象征音乐更好、更有力的分析和理解,我们可以修复和控制音乐原理的具体音乐方面,如和弦(和弦本身或其质量、反转等)、节奏执行(琶音、保持和弦等)或高级结构特征,如每个小节的关键。
2) 乐谱维护
a) 钢琴音乐:钢琴音乐基本上是合成复调音乐,它有一个旋律和一个与旋律连贯的伴奏或和弦序列。由于过去缺乏能够处理多乐器音乐的强大模型,研究人员一直专注于这类音乐。从这个角度来看,钢琴音乐模式与我们根据纹理分类的旋律和伴奏生成模式是一样的。这是因为钢琴是一种复调乐器,我们可以用它同时演奏旋律和伴奏,而现有的复调音乐数据集大多是钢琴数据集,蓝调或爵士乐数据集除外。
b) 多乐器音乐:多音轨或多乐器音乐是指为多个乐器创作或编排的音乐。请注意,这种分类与纹理不同,因为多乐器音乐也可以写成带有伴奏或其他纹理的旋律。多种乐器的音乐给钢琴音乐增加了额外的难度,因为作品中有更多的信息(更多的音符),而且它增加了处理每种乐器的符号和演奏属性以制作连贯作品的问题。在图 4 中,我们展示了该方案,该方案具有多种乐器的类似输出的乐谱的音乐基本原理。
多音轨生成的第一种方法是在作品中加入鼓的音轨。由于鼓是非音高的乐器,因此使用鼓就能实现与旋律的节奏相匹配。2012 年,Kang 等人提出了一个模型,该模型可以为旋律和鼓生成和弦伴奏。2017 年,Chu 等人提出了具有分级 RNN 的 PI 之歌。2017 年,第一个为多音高乐器生成连贯音乐的模型是 MuseGAN。从那时起,提出了更多基于 GAN 的模型,如 SeqGAN 或具有二元神经元的 CNN-GAN。后来,正如钢琴音乐一样,基于 Transformer 的模型被开发用于多音轨音乐。2019 年,Donahue 等人提出了 LakhNES,这是一个基于 TransformerXL 并使用 NES 音乐数据库(NES-MDB)进行训练的模型。2020 年,针对这项任务,还提出了更多具有不同编码的基于 Transformer 的模型(见表IV)。其中一些模型使用了它自己的编码,我们在本节前面的序列编码段落中对此进行了描述。Ens 等人提出了 MMM 编码,该编码通过使用 Hugging Face Transformers 库在文本上使用 GPT-2 预训练模型进行训练。2020 年发布的其他型号包括使用 MuMIDI 编码的 Pop-MAG 型号、使用 OctupleMIDI 编码的 MusicBERT 型号、使用 REMI 编码的 Pop Music Transformer 型号和使用音乐 BPE 算法获得的 MMR 编码的 SymphonyNet 型号。其他工作涉及符号音乐理解的基于 Transformer 的模型的预训练。需要注意的是,由于这些模型需要在我们从头开始训练它们的情况下训练大型数据集(如果我们查看之前提到的数据集,则需要超过 50 万个文件),因此编码算法的计算成本对于加速标记化过程非常重要。同样值得注意的是,减少了令牌的数量,并使用了不是线性的,而是以一种可以像 SymphonyNet 那样耦合令牌的方式,使训练和推理更快。值得一提的是,尽管音乐转换器的编码是为钢琴作品设计的,但它可以被修改为对多音轨音乐进行编码,或者使用预先训练的模型对多音轨数据集进行迁移学习。
c) 乐器和编排:乐器和编排可能不像旋律位置那样重要,但它们在作曲过程中发挥着重要作用。然而,在音乐生成领域,人们对这些技术的兴趣并不高,可能是因为该领域中使用的模型和数据集还没有开发到足以应对这些问题的程度。正如我们在第三节中介绍的,插入和编排是不同的技术。第一个是选择符合其音乐和演奏特性的乐器,第二个是选择和排列音乐信息的过程。关注那些试图面对和建模这些技术的 DL 模型,我们可以找到 SymphonyNet,它是在 2022 年提出的。它使用基于 BERT 的模型和标记化,以便对模型进行训练,以对音符所属的乐器进行分类。这是 DL 模型的音乐乐器和配器的第一个和成功的想法之一。然而,重要的是要注意,从模型的角度来看,它同时学习这两种技术,并且不区分它们。例如,用这些技术可以将钢琴作品转换为管弦乐队作品,但 SymphonyNet 是用管弦乐队作品直接训练的,这意味着它不能将钢琴作品转化为管弦乐队,也不能减少管弦乐队的钢琴作品。